
“Close-up of Caucasian mother and baby girl sitting at windowsill and reading book. Young woman educating daughter at home”

1Huazhong University of Science and Technology, 2Alibaba Group, 3Zhejiang University, 4Ant Group
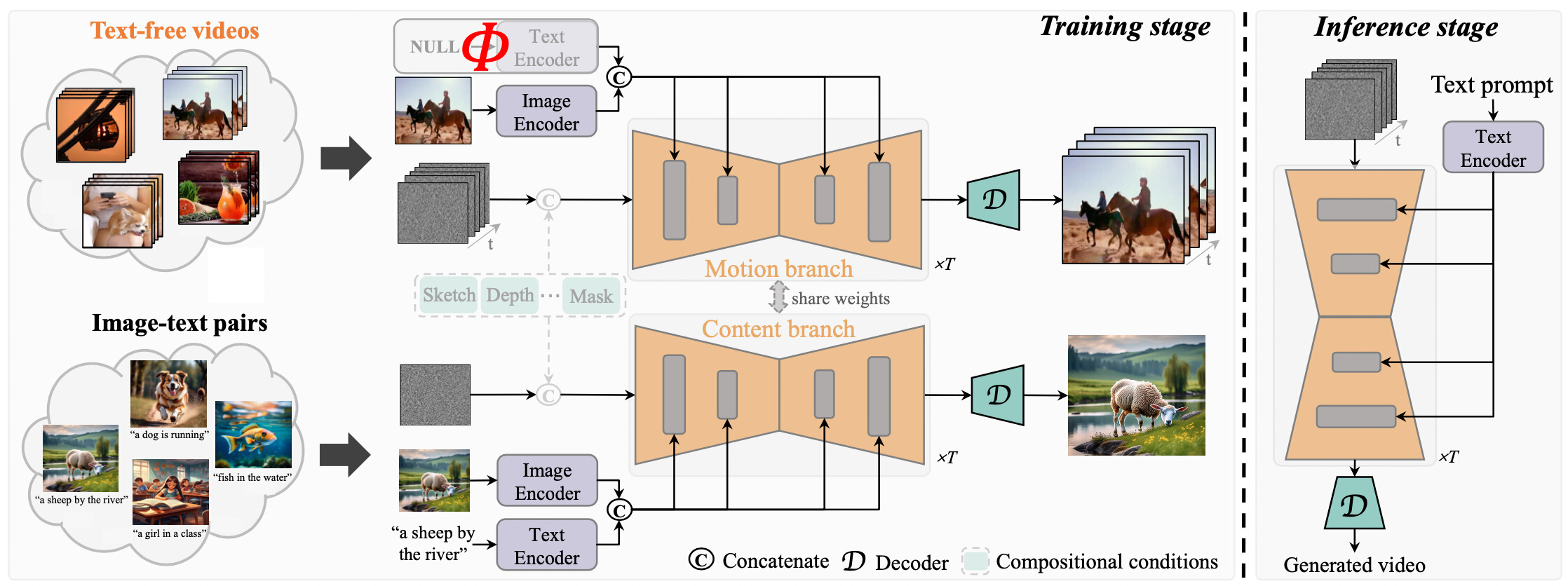
Diffusion-based text-to-video generation has witnessed impressive progress in the past year yet still falls behind text-to-image generation. One of the key reasons is the limited scale of publicly available data (e.g., 10M video- text pairs in WebVid10M vs. 5B image-text pairs in LAION), considering the high cost of video captioning. Instead, it could be far easier to collect unlabeled clips from video platforms like YouTube. Motivated by this, we come up with a novel text-to-video generation framework, termed TF-T2V, which can directly learn with text-free videos. The rationale behind is to separate the process of text decoding from that of temporal modeling. To this end, we employ a content branch and a motion branch, which are jointly optimized with weights shared. Following such a pipeline, we study the effect of doubling the scale of training set (i.e., video-only WebVid10M) with some randomly collected text-free videos and are encouraged to observe the performance improvement (FID from 9.67 to 8.19 and FVD from 484 to 441), demonstrating the scalability of our approach. We also find that our model could enjoy sustainable performance gain (FID from 8.19 to 7.64 and FVD from 441 to 366) after reintroducing some text labels for training. Finally, we validate the effectiveness and generalizability of our ideology on both native text-to-video generation and compositional video synthesis paradigms. Code and models will be made public here.
“Close-up of Caucasian mother and baby girl sitting at windowsill and reading book. Young woman educating daughter at home”

“Capsule Being Tested in a Dissolution Apparatus”

“Elegant Swans On A Misty Lake”

“A Tyrannosaurus Rex stalks through a forest”

“man uses a virtual reality glasses against the skyscrapers sky”

“wild blueberry in autumn colors on wooden table”

“A water based Axolotl warrior, Pokémon inspiration, Pixar animated art style”

“Mature businesswoman using computer in office”

“Old homeless white dog with a sore paw eats from an iron bowl peeking out of the doghouse in animal shelter”

“Lindsay was a magical teacher with a unique teaching style, cartoon style, dreamlike, hyperdetailed, 8k, hyperealistic”

“league of legends, trippy scenery, insanely detailed”

“Young woman trekking and enjoying in the woods, holidays and traveling concept”

“A water based Axolotl warrior, Pokémon inspiration, Pixar animated art style”

“european woman holding a lightsaber in a wielding position with neon lights around her, realistic style”

“Satoru Gojou from jujutsu Kaisen, very handsome and semi muscular, hyper realistic, photorealistic, Studio Lighting, Depth of Field”

“portrait realistic seaside female 25-30 american fashionable”

“Colorful leaves moving in the wind”

“Las Nubes waterfall in Chiapas”

“Cute little Asian girl playing with a teddy bear on a motorbike”

“Driving Along Amish Countryside Came Across an Amish Man on a Scooter”

“cute alpacas, pixa, max details”

“a cavern with a pedestal in it's center with a small glowing orb on top of it”

“Beautiful 20 year old female, ginger with volumized hair and curls, dressed up as a vampire for a halloween party”

“Tre Cime di Lavaredo, Dolomites, Italian Alps, Italy”

“wren, with watercolour splash background, clip art illustration, line drawing, watercolour drawing”

“Flowing abstract and mystical orange flowers in underwater space”

“gorgeous Latina, light brown hair, honey brown eyes, honey glowing skin, goddess, looking towards you”

“happy cute cartoon hedgehog hugs a flower, white background, fantasy mood, incredibly detailed”

“portrait of a small young artist women with orange air, similing with innoncence while she paint”

“Basket of fresh wasabi plants”

“Blonde bride in fashion white wedding dress with makeup”

“blonde female texting on mobile in flat”

“valentines background with hearts, professional food photography with lots of copy space UHD 8k”

“Mahatma Gandhi, wearing a Mario costume complete with the iconic red cap, blue overalls, and red shirt, strikes a playful pose as he embraces the spirit of the famous video game character”

“Senior Romantic Couple Outside”

“Cartoon pug dog, shy smile, fantasy, dreamlike, super cute, 8k, highly detailed, intricate, award-wining, cinematic, beautiful light, 100mm”

“Steaming Mug”

“Portrait Of Male Elementary School Teacher Standing In Classroom”

“a house model on a white desk with perfect white lighting from the top”

“logo of a cartoon bee for a candy company”

“Smiling future mother using computer sitting near window”

“Modern interior living room background, a rose bouquet, butterflies and flowers in the style of painting, with a green chair and lights for the table and ceiling”

“white fluffy cat in shabby chic bedroom, in the style of soft-focus portraits, white and azure”

“Man with vibrant red skin and gray facial markings wearing a black tshirt and brown jacket, red skin, realistic proportions, 8k, ultra detailed, hyperrealistic, raytracing, realistic skin texture”

“Nature scenery around Bukhangang River and Water Garden in Joan County in Namyangju-si and Yangseo County / Yangpyeong-gun, Gyeonggi-do, South Korea”

“Skin care cosmetics products in bottles appear on the table”

“A photo of a beautiful 35 year thai woman with black hair wearing a jacket and tattoos as accessories, with a smiling expression on her face and light facial features. The background is a thai subway station. The composition focuses on the woman with the tube station in the background...”

“Adorable hispanic girl smiling confident standing on cradle at bedroom”
“Modern interior living room background, a rose bouquet, butterflies and flowers in the style of painting, with a green chair and lights for the table”

“futuristic fantasy motorcycle, symmetric, detailed, hyperrealistic”

“A magpie is singing and standing on a tall branch, there are some beautiful cherry blossoms in front of the lens”

“White millennial girl texting on cellphone, smiling outdoors by the bay or water”

“illustration with bright colors, main theme - garden, ar 3:4”

“Baby inside crib wanting attention. Happy smiling toddler boy”

“Little black havanese dog in strong space armor unreal engine 5”

“infrared photography, dreamy enchanted forest with large and small birch trees, mushrooms, flowers, foxglove, sparkles, vector graphics, by Olga Boznańska, Shutterstock, light effect, feminine, bright butterflies...”

“a frost bulky creature in a snow covered landscape. It wields a large spiky ice club. realistic”

“Portrait of female employee working in an urban office”

“Beautiful turquoise water alpine lake in Dolomites mountains, Belluno, Italy. Aerial view”

“Senior hispanic man suffering from headache feeling desperate and stressed”


“Charming young girl with flowers.”


"Close up of a young girl drawing on a chalkboard"


"waking in the jungle"


"Student in eyeglasses laughing at camera. Businessman posing at camera outdoors"


“Black woman, skincare and glow with smile while hand touch shoulder to feel smooth texture. Model, happy and skin with soft, healthy and wellness for portrait with beauty, cosmetics and dermatology”


"Young african american woman talking on the smartphone and using credit card at street"


"Close up to male face of young farmer examining his golden wheat field. Young agronomist standing on barley meadow and enjoying his cereal plantation. Concept of agricultural business. Slow motion"


"Close up portrait A beautiful young girl in a white T-shirt is chatting in social networks on her smartphone while sitting on a bench in a park"


“Casual Joyful South American man checking smartphone walking in city street in daylight. Smiling hispanic person using phone”

"A young spotted hyena at its den, Kruger National Park, South Africa"


"Working from home - chroma key screen on the laptop"


"Executives discussing over laptop 4k"

“Blue 3D numbers growing up”


“Absorbed African American happy man reading book lying on bed at home indoors. Portrait of smart confident relaxed guy enjoying hobby in the evening in bedroom. Lifestyle and joy concept”


“A model with long hair, 30-35 years old, wearing a hat and sunglasses.”


“Young blonde woman with serious expression standing at street”

“Close-up of chess on a black background. Wooden chess pieces. Concept: the Board game and the intellectual activities”


“CU Owl perching on stares tree / Winnipeg, Manitoba, Canada”





















“A dog is running away from the camera”

“A man is running from right to left”

“Beautiful peonies are blooming on a black background”

“A manor, a rotating view”
1Huazhong University of Science and Technology, 2Alibaba Group, 3Shanghai Jiao Tong University,
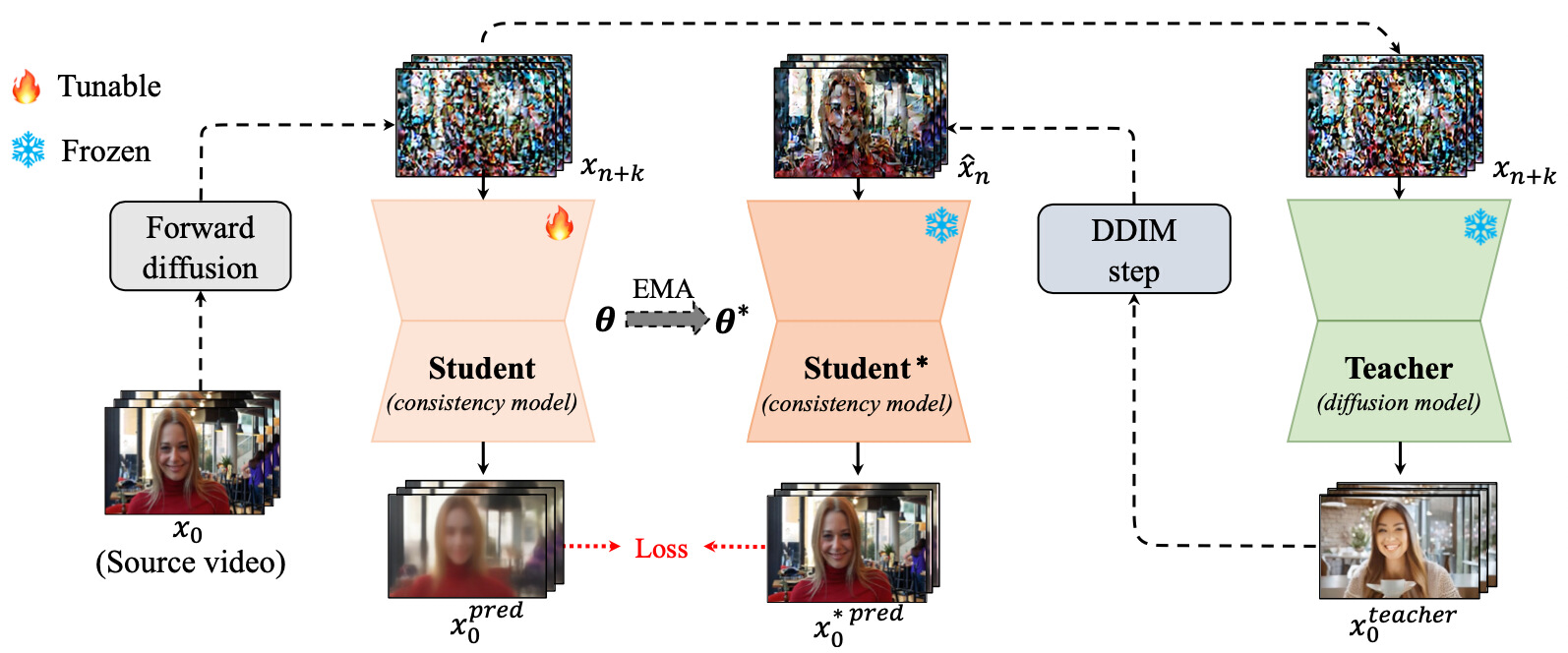
Consistency models have demonstrated powerful capability in efficient image generation and allowed synthesis within a few sampling steps, alleviating the high computational cost in diffusion models. However, consistency model in the more challenging and resource-consuming video generation is still less-explored. In this report, we present the VideoLCM framework to fulfill this gap, which leverages the concept of consistency models from image generation to efficiently synthesize videos with minimal steps while maintaining high quality. VideoLCM builds upon existing latent video diffusion models and incorporates distillation techniques for training the latent consistency model. Experimental results reveal the effectiveness of our VideoLCM in terms of computational efficiency, fidelity and temporal consistency. Notably, VideoLCM achieves high-fidelity and smooth video synthesis with only 4 sampling steps, showcasing the potential for real-time synthesis. We hope that VideoLCM can serve as a simple yet effective baseline for subsequent research work.

“Beef burger in close up”

"Young woman using a laptop while working at home"

"Rocks Splash Ocean Close Up (HD)"

"girl paints eyes with mascara"


“Monarch butterfly drinking nectar”


"Fruitfully young red grapes hanging on vineyard, hanging on a bush in a beautiful sunny day."


"instant noodle spicy salad with pork onplate - Asian food style"


"Beautiful woman playing with her hair"

“Portrait of infant boy looking to camera”


"Man wearing protective suit showing palms with inscription"


"Pleased brunette woman talking by smartphone and looking around"

"A girl is standing in smoke holding a mask in her hand. White smoke."
@article{TFT2V,
title={A Recipe for Scaling up Text-to-Video Generation with Text-free Videos},
author={Wang, Xiang and Zhang, Shiwei and Yuan, Hangjie and Qing, Zhiwu and Gong, Biao and Zhang, Yingya and Shen, Yujun and Gao, Changxin and Sang, Nong},
journal={arXiv preprint arXiv:2312.15770},
year={2023}
}
@article{wang2023videolcm,
title={Videolcm: Video latent consistency model},
author={Wang, Xiang and Zhang, Shiwei and Zhang, Han and Liu, Yu and Zhang, Yingya and Gao, Changxin and Sang, Nong},
journal={arXiv preprint arXiv:2312.09109},
year={2023}
}
@article{videocomposer,
title={VideoComposer: Compositional Video Synthesis with Motion Controllability},
author={Wang, Xiang and Yuan, Hangjie and Zhang, Shiwei and Chen, Dayou and Wang, Jiuniu and Zhang, Yingya and Shen, Yujun and Zhao, Deli and Zhou, Jingren},
journal={NeurIPS},
year={2023}
}